

算力不足,小模型成AI模型发展下个方向?

大型模型并不是人工智能的唯一发展方向,将模型进行精简也是一种技能。
这段时间,人工智能模型领域非常热闹,不断涌现出新的模型。无论是开源还是闭源,这些模型都在不断刷新成绩。就在前几天,Meta发布了Llama 3 8B和70B两个版本,这两个版本在多项指标上都超过了之前开源的Grok-1和DBRX,成为了新的开源大模型的王者。

并且Meta还透露,之后还将推出400B版本的Llama 3,它的测试成绩可是在很多方面上都追上了OpenAI闭源的GPT-4,让很多人都直呼,开源版的GPT-4就要来了。尽管在参数量上来看,相比Llama 2,Llama 3并没有特别大的提升,但是在某些表现上,Llama 3最小的8B版本都比Llama 2 70B要好。可见,模型性能的提升,并非只有堆参数这一种做法。
Llama 3重回开源之王
当地时间4月18日,“真·OpenAI”——Meta跑出了目前最强的开源大模型Llama 3。本次Meta共发布了两款开源的Llama 3 8B和Llama 3 70B模型。根据Meta的说法,这两个版本的Llama 3是目前同体量下,性能最好的开源模型。并且在某些数据集上,Llama 3 8B的性能比Llama 2 70B还要强,要知道,这两者的参数可是相差了一个数量级。

能够做到这点,可能是因为Llama 3的训练效率要高3倍,它基于超过15T token训练,这比Llama 2数据集的7倍还多。在MMLU、ARC、DROP等基准测试中,Llama 3 8B在九项测试中领先于同行,Llama 3 70B也同样击败了Gemini 1.5 Pro和Claude 3 Sonnet。
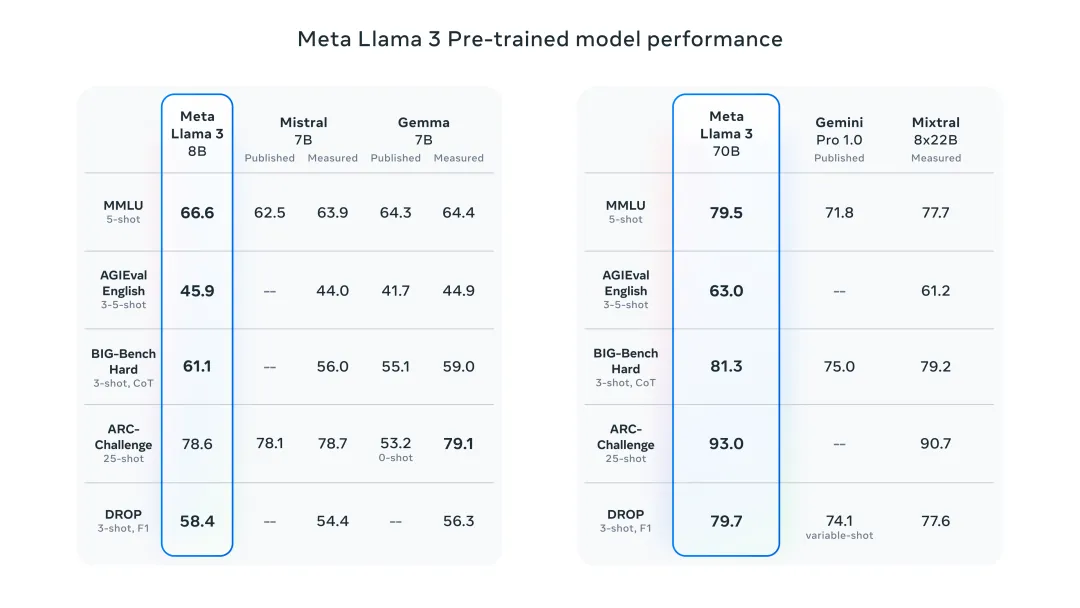
尽管在参数量上并没有特别大的提升,但毫无疑问,Llama 3的性能已经得到了很大的提升,可以说是用相近的参数量获得了更好的性能,这可能是在算力资源短期内无法满足更大规模运算的情况下所作出的选择,但这体现了AI模型的研发并非只有堆砌参数这一条“大力出奇迹”的道路。
将大型模型缩小已成为业内共识
实际上,在Llama 3之间的两位开源王者,Grok-1和DBRX也致力于将模型变得更小。与以往只使用一个模型解决所有问题的方式不同,Grok-1和DBRX采用了MoE架构(专家模型架构),当面对不同问题时,它们会调用不同的小模型来解决,以在节省算力的同时保证回答的质量。

而微软也在Llama 3发布后没几天,就出手截胡,展示了Phi-3系列小模型的技术报告。在这份报告中,仅3.8B参数的Phi-3-mini在多项基准测试中都超过了Llama 3 8B,并且为了方便开源社区使用,还特意把它设计成了与Llama系列兼容的结构。更夸张的是,微软的这个模型,在手机上也能直接跑,经过4bit量化后的phi-3-mini在iPhone 14 pro和iPhone 15使用的苹果A16芯片上能够每秒处理12个token,这也就意味着,现在手机上能本地运行的最佳开源模型,已经达到了ChatGPT的水平。
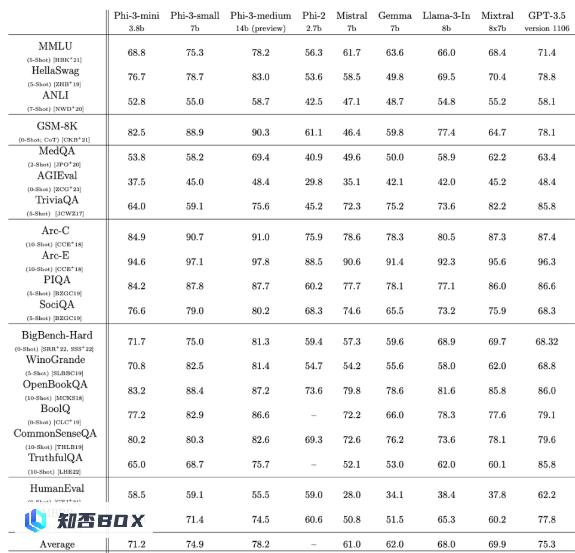
而除了mini杯外,微软也一并发布了小杯和中杯,7B参数的Phi-3-small和14B参数的Phi-3-medium。在技术报告中,微软也提到,去年研究团队就发现,单纯增加参数量并非提升模型性能的唯一途径,相反,通过精心设计训练数据,特别是利用大模型本身生成合成数据,并结合严格过滤的高质量数据,可以显著提升中小模型的能力。因此,他们也强调,教科书级别的高质量数据才是至关重要的。

AI模型发展正着力于摆脱限制
AI模型的发展目前正致力于摆脱各种限制。英伟达凭借其强大的人工智能技术,成为行业内无可争议的领导者,被誉为“卖铲子的人”。各家人工智能公司都将英伟达的GPU视为稀缺资源,以至于谁拥有更多的英伟达GPU,谁的人工智能实力就更强大。然而,英伟达的GPU供应并未能始终满足市场需求。
因此,很多人工智能(AI)公司开始寻找其他的图形处理器(GPU)生产商,或者决定自己研发AI芯片。即使你囤够了英伟达的GPU,也会面临其他限制。最近,OpenAI因为训练GPT-6的过程中,差点导致微软的电网瘫痪。埃隆·马斯克也曾表示,目前限制AI发展的主要因素是算力资源,但在未来,电力供应将成为另一个限制AI发展的障碍。

显然,如果持续“大力出奇迹”,通过增加参数数量来提升AI性能,那么以上这些问题迟早会遇到。但是,如果我们能够将大型模型缩小,使用较少的参数数量,却能实现相同甚至更好的性能,那么就能显著减少对算力资源的需求,进而减少对电力资源的消耗。这样,在有限资源的情况下,AI的发展将会更好。
因此,接下来,谁能在将模型缩小的同时,还能实现性能的提升,也是实力的体现。


相关推荐
查看更多


